#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define size 10
/*
8.8 중복있는 순열
문자열이 주어졌을 때 모든 경우의 순열을 계산하는 메서드를 작성하라.
나열된 순열은 서로 중복되면 안된다.
*/
void swap(char *s, char *t) {
char temp;
temp = *s;
*s = *t;
*t = temp;
}
void permutation(char *s, int l, int r) {
if (l == r)
printf("%s\n", s);
else {
for (int i = l; i <= r; i++) {
swap((s + l), (s + i));
permutation(s, l + 1, r);
swap((s + l), (s + i));
}
}
}
int main() {
char a[size];
printf("문자열을 입력하세요 : ");
scanf("%s", &a);
int n = strlen(a);
permutation(a, 0, n - 1);
}
[동작 과정]
1. i번째 요소(그림에서 표현한 빨간 문자)와 left 인덱스에 있는 요소의 위치를 바꿔준다. (아래 수식의 a1,a2,a3)
2. left 인덱스 다음에 있는 나머지 요소들의 순열을 구한다. (위의 수식의 P(a1a2),P(a1a3),P(a2a3))
3. 다음 순열에 영향을 주지 않도록 배열 요소들의 위치를 되돌려 놓는다.
4. 배열의 마지막 인덱스에 다다르면 해당 문자열을 출력한다.
[수행 시간]
permutation 함수가 배열의 길이(n)만큼 실행된다. 그 다음 함수에서는 n-1번, n-2번, ... 만큼 실행되므로 총 n! 번 호출된다. 말단 노드의 개수는 n!개이고, 각 루트에서 말단 노드까지의 거리는 n이므로, 전체 노드(함수 호출)의 개수는 n*n!을 넘지 못한다. 총 시간 복잡도는 O(n*n!)이다.
시간당 수백 명의 고객을 상대하며 여러 가지의 제품을 만들어 내야 하는 대규모 식당에 설치되는 기계,
나이 드신 분들이 사용하는, 블랙 커피만 만드는 간단한 기계 등 여러 용도에 따라 설계 자체가 완전히 바뀜.
2단계 : 핵심 객체의 설계
무엇을 설계할 것인지 이해했으므로 시스템에 넣을 '핵심 객체(core object)'가 무엇인지 생각해 봐야 한다.
ex. 식당
핵심 객체 : Table, Guest, Order, Meal, Employee, Server 등
3단계 : 관계 분석
객체 사이의 관계를 분석. 한 객체가 다른 객체에 속해 있는지(member), 상속받아야 하는지(inherit), 다-대-다(many-to-many) 관계인지 혹은 일-대-다 관계인지 등.
ex. 식당
- Server와 Host는 Employee를 상속받는다.
- 각 Table은 Party를 하나만 가질 수 있지만, 각 Party는 Tables을 여러 개 가질 수 있다.
- Restaurant에 Host는 한 명뿐이다.
주의할 점 : 종종 잘못된 가정을 만들어 사용하는 경우를 피해야 함. (하나의 Table에 여러 Party가 앉는 경우도 있음.)
설계가 얼마나 일반적이어야 하는지에 관해서는 면접관과 상의한 후 결정하는 것이 좋다!
4단계 : 행동 분석
객체 지향 설계의 골격이 어느 정도 잡힌 상태가 된 후, 이제 객체가 수행해야 하는 핵심 행동들에 대해서 생각하고,
이들이 어떻게 상호작용해야 하는지 따져 보는 것이다. 깜박 잊은 객체가 있을 수도 있고 상황에 따라 설계를 변경해야 할 수도 있다.
ex. 식당 -> 한 Party가 Restaurant에 입장하고, 한 Guest가 Host에게 Table을 부탁한 경우.
Host는 Reservation을 살펴본 다음 자리가 있으면 해당 Party에게 Table을 배정할 것이다.
자리가 없다면 Party는 Reservation 리스트 맨 마지막에 추가될 것이다.
한 Party가 식사를 마치고 떠나면 한 Table이 비게 되고, 그 테이블은 리스트의 맨 위 Party에게 하당될 것이다.
디자인 패턴
- Singleton class
어떤 클래스가 하나의 객체만을 갖도록 하며, 프로그램 전반에 걸쳐 그 객체 하나만 사용되도록 보장해야 한다.
정확히 하나면 생성되어야 하는 전역 객체를 구현해야 하는 경우에 특히 유용하다.
ex. Restaurant 클래스는 정확히 하나의 객체만 갖도록 구현하는 것이 좋다.
- factory method
어떤 클래스의 객체를 생성하기 위한 인터페이스를 제공하되, 하위 클래스에서 어떤 클래스를 생성할지 결정할 수 있도록 도와준다. 이를 구현하는 한 가지 방법은, 메서드 자체에 대한 구현은 제공하지 않고, 객체 생성 클래스를 abstract로 선언하고 놔두는 것이다. 또 다른 방법으로는, Factory 메서드를 실제로 구현한 Creator 클래스를 만드는 것이다.
스택 자료구조는 말 그대로 데이터를 쌓아 올린다는 의미이다. 문제의 종류에 따라 배열보다 스택에 데이터를 저장하는 것이 더 적합한 방법일 수 있다.
스택은 LIFO(Last-In-First-Out)에 따라 자료를 배열한다. 가장 최근에 스택에 추가한 항목이 가장 먼저 제거될 항목이다.
pop() : 스택에서 가장 위에 있는 항목을 제거한다.
push(item) : item 하나를 스택의 가장 윗 부분에 추가한다.
peek() : 스택의 가장 위에 있는 항목을 반환한다.
isEmpty() : 스택이 비어 있을 때에 true를 반환한다.
스택은 배열과 달리, 상수 시간에 i번째 항목에 접근할 수 없다. 하지만 데이터를 추가하거나 삭제하는 연산은 상수 시간에 가능하다. 배열처럼 옆으로 밀어 줄 필요가 없다! 연결리스트로도 구현 가능함.
public class MyStack {
private static class StackNode{
private T data;
private StackNode next;
public StackNode(T data){
this.data=data;
}
}
private StackNode top;
public T pop(){
if(top==null) throw new EmptyStackException();
// 스택이 비어있는 것을 나타냄.
T item=top.data;
top=top.next;
return item;
}
public void push(T item){
StackNode t=new StackNode(item);
t.next=top;
top=t;
}
public T peek(){
if(top==null) throw new EmptyStackException();
return top.data;
}
public boolean isEmpty(){
return top==null;
}
}
스택이 유용한 경우는 재귀 알고리즘을 사용할 때다. 재귀적으로 함수를 호출해야 하는 경우에 임시 데이터를 스택에 넣어 주고, 재귀 함수를 빠져 나와 퇴각 검색을(backtrack) 할 때에는 스택에 넣어 두었던 임시 데이터를 빼 줘야 한다.
연결리스트로 구현한 스택의 push와 pop
큐 구현
큐는 FIFO(First-In-First-Out) 순서를 따르고, 큐에 추가되는 순서대로 제거된다.
add(item) : item을 리스트의 끝부분에 추가한다.
remove() : 리스트의 첫 번째 항목을 제거한다.
peek() : 큐에서 가장 위에 있는 항목을 반환한다.
isEmpty() : 큐가 비어 있을 때에 true를 반환한다.
큐도 연결리스트로 구현할 수 있는데, 연결리스트의 반대 방향에서 항목을 추가하거나 제거하도록 구현한다면 근본적으로 큐와 같다.
public class MyQueue{
private static class QueueNode {
private T data;
private QueueNode next;
public QueueNode(T data){
this.data=data;
}
}
private QueueNode first;
private QueueNode last;
public void add(T item){
QueueNode t=new QueueNode(item);
if (last!=null) {
last.next=t;
}
last=t;
if (first==null){
first=last;
}
}
public T remove() {
if (first==null) throw new NoSuchElementException();
T data=first.data;
first=first.next;
if (first==null) {
last=null;
}
return data;
}
public T peek(){
if(first==null) throw new NoSuchElementException();
return first.data;
}
public boolean isEmpty(){
return first==null;
}
}
큐에서 처음과 마지막 노드를 갱신할 때 실수가 자주 나오므로 확인 꼭 하기!
큐는 너비 우선 탐색(BFS)을 하거나 캐시를 구현하는 경우 종종 사용된다.
Ex) 너비 우선 탐색의 경우 : 처리해야 할 노드의 리스트를 저장하는 용도로 사용한다. 노드를 하나 처리할 때마다 해당 노드와 인접한 노드들을 큐에 다시 저장한다. 이런식으로, 접근한 순서대로 처리할 수 있게 된다.
배열과는 달리, 특정 인덱스를 상수 시간에 접근할 수 없다. 리스트에서 k번째 원소를 찾고 싶다면, 처음부터 k번 루프를 돌아야 한다.
단방향 연결리스트의 예
한 노드는 [데이터 + 다른 노드를 가리키는 포인터]로 이루어져 있다. 처음 시작하는 노드는 head 노드인데, 단일 연결리스트를 구현하는 데 필수적이다. 맨 처음 노드(위에서 data 3을 가지고 있는 노드)의 주소를 담기 위해서 head를 사용한다.
연결리스트의 장점 : 리스트의 시작 지점에서 아이템을 추가하거나 삭제하는 연산을 상수 시간에 할 수 있다.
연결리스트의 구현
기본적인 단방향 연결리스트 구현
class Node{
Node next=null;
int data;
public Node(int d) {
data=d;
}
void appendToTail(int d){
Node end=new Node(d);
Node n=this;
while (n.next!=null) {
n=n.next;
}
n.next=end;
}
}
위의 코드에서는, LinkedList 자료구조를 사용하지 않고, 연결리스트에 접근할 때 head노드의 주소를 참조하는 방법을 사용하였다. 이 때, 여러 객체들이 동시에 연결리스트를 참조하는 도중에 head가 바뀐다면, 어떤 객체들은 이전 head를 계속 가리키고 있을 수도 있다.
할 수 있다면, Node 클래스를 포함하는 LinkedList클래스를 만드는 게 좋다.
이런 식으로 한다면, 해당 클래스 안에 head Node 변수를 단 하나만 정의해 놓음으로써 위 문제점을 완전히 해결한다.
면접에서, 단방향 연결리스트인지 양방향 연결리스트인지 반드시 인지하고 있어야 한다!
단방향 연결리스트에서 노드 삭제
삭제할 노드 n이 주어지면 그 이전 노드 prev를 찾아 prev.next를 n.next와 같도록 설정한다.
양방향 연결리스트인 경우, n.next가 가리키는 노드를 갱신하여 n.next.prev가 n.prev와 같도록 설정해야 한다.
유의할 점
널 포인트 검사를 해야 한다.
head와 tail 포인터도 갱신해줘야 한다.
C나 C++처럼 메모리 관리가 필요한 언어를 사용해 구현하는 경우에는, 삭제한 노드에 할당한 메모리가 제대로 반환되었는지 반드시 확인해줘야 함.
Node deleteNode(Node head, int d){
Node n=head;
if (n.data==d){
return head.next; /*head를 움직인다*/
}
while(n.next!=null){
if(n.next.data==d){
n.next=n.next.next;
return head; /*head는 변하지 않는다.*/
}
n=n.next;
}
return head;
}
Runner 기법
Runner (부가 포인터 라고도 함)는 연결리스트 문제에서 많이 활용되는 기법이다.
연결리스트를 순회할 때 두 개의 포인터를 동시에 사용하는 것이다. 이때 한 포인터가 다른 포인터보다 앞서도록 한다.
앞선 포인터가 따라오는 포인터보다 항상 지정된 개수만큼을 앞서도록 할 수도 있고, 아니면 따라오는 포인터를 여러 노드를 한 번에 뛰어넘도록 설정할 수도 있다.
예를 들어, 연결리스트 a1->a2->...->an->b1->b2->...->bn이 있다고 하자.
이 연결리스트를 a1->b1->a2->b2->...->an->bn과 같이 재정렬하고 싶다고 한다. 연결리스트의 정확한 길이는 모르지만, 길이는 짝수라는 정보가 주어졌다.
-> 이때, 포인터 p1(앞선 포인터)를 두고, 따라오는 포인터 p2가 한 번 움직일 때마다 포인터 p1이 두 번 움직이도록 설정해 보자. 그랬을 때 p1이 연결리스트 끝에 도달하면 p2는 가운데 지점에 있게 될 것이다. 이 상태에서 p1을 다시 맨 앞으로 옮긴 다음 p2로 하여금 원소를 재배열하도록 만들 수 있다. 즉, 루프가 실행될 때마다 p2가 가리키는 원소를 p1뒤로 옮기는 것이다.
재귀 문제
대부분의 연결리스트 문제는 재귀 문제이다. 재귀 호출 깊이가 n이 될 경우, 해당 재귀 알고리즘이 적어도 O(n)만큼의 공간을 사용한다는 사실을 기억하자. 모든 재귀 알고리즘은 반복적 형태로도 구현될 수있긴 하지만 반복적 형태로 구현하면 한층 복잡해질 것이다.
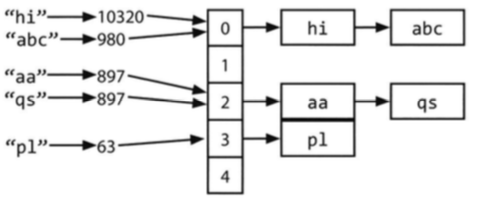
효율적인 탐색을 위한 자료구조로서 key를 value에 대응시키는 것. 구현하는 방법은 여러 가지가 있는데, 연결리스트와 해시 코드 함수를 통해 간단한 해시 테이블을 구현한다. key는 문자열 혹은 어떤 자료형도 가능하다.
key의 hash code를 계산한다. 키의 자료형은 보통 int나 long이 된다. key의 개수는 무한한데, int의 개수는 유한하기 때문에 서로 다른 두 개의 키가 같은 해시 코드를 가리킬 수 있음.
hash(key) % array_length와 같은 방식으로 해시 코드를 이용해 배열의 인덱스를 구한다. 물론 서로 다른 두 개의 해시 코드가 같은 인덱스를 가리킬 수도 있음.
배열의 각 인덱스에는 키와 값으로 이루어진 연결리스트가 존재한다. 키와 값을 해당 인덱스에 저장한다. 충돌에 대비해서 반드시 연결리스트를 이용해야 한다. 여기서 충돌이란 서로 다른 두 개의 키가 같은 해시 코드를 가리키거나 서로 다른 두 개의 해시 코드가 같은 인덱스를 가리키는 경우를 말한다.
주어진 키로부터 해시 코드를 계산하고, 이 코드를 이용하여 인덱스를 계산한다. 그 다음 해당 키에 상응하는 값에 상응하는 값 연결리스트에서 탐색하면 된다.
충돌이 자주 발생한다면, 최악의 경우의 수행 시간은 O(n) (n은 키의 개수)가 된다. 일반적으로는 충돌을 최소화하도록 잘 구현된 경우를 가정하는데 이 경우에 탐색 시간은 O(1)이다.
★★ ArrayList와 가변 크기 배열
특정 언어에선, 배열의 크기를 자동으로 조절할 수 있다. 데이터를 덧붙일 때마다 배열 혹은 리스트의 크기가 증가한다.
하지만 자바 같은 언어에서는 배열의 길이가 고정되어 있다. 이런 경우에는 배열을 만들 때 배열의 크기를 함께 지정해야 한다.
동적 가변 크기 기능이 내재되어 있는 배열과 비슷한 자료구조를 원할 때는 보통 ArrayList를 사용한다. 필요에 따라 크기를 변화시킬 수 있으면서도 O(1)의 접근 시간을 유지한다. 배열이 가득차는 순간, 배열의 크기를 두 배로 늘린다.
크기를 두 배 늘리는 시간은 O(n)이지만, 자주 발생하는 일은 아니기 때문에 amortized insertion time으로 계산하면 O(1)이다.
ArrayList merge (String[] words, String[] more){
ArrayList sentence=new ArrayList();
for (String w : words) sentence.add(w);
for (String w : more) sentence.add(w);
for (String w : more) sentence.add(w);
return sentence;
}
위의 경우, O(n)시간과 O(n)공간을 사용한다. 호출될 때마다, 스택의 깊이가 깊어져, sum(4)->sum(3)->...->sum(0)의 호출이 일어난다.
int pariSumSequence(int n) {
int sum=0;
for (int i=0;i<n;i++){
sum+=pairSum(i,i+1);
}
return sum;
}
int pairSum(int a,int b){
return a+b;
}
위의 경우, pairSum함수를 마찬가지로, O(n)번 호출하였지만, 이 함수들이 호출 스택이 동시에 존재하지는 않으므로 O(1) 공간만 사용하는 것을 볼 수 있다.
여러 부분으로 이루어진 알고리즘 : 덧셈 vs 곱셈
알고리즘이 두 단계일 때, 어떨 때는 더하고 어떨 때는 곱해야 할까?
만약 알고리즘이 "A일을 모두 끝마친 후에 B 일을 수행하라"의 형태라면 O(A+B)
만약 알고리즘이 "A일을 할 때마다 B일을 수행하라"의 형태라면 O(A*B)
상환 시간
ArrayList는 배열의 역할을 함과 동시에 크기가 자유롭게 조절되는 자료구조이다. 원소 삽입 시 필요에 따라 배열의 크기를 증가시킬 수 있기 때문에 공간이 바닥날 일은 없다.
ArrayList는 배열로 구현이 되어 있는데, 배열의 용량이 꽉 찼을 때, ArrayList 클래스는 기존보다 크기가 두 배 더 큰 배열을 만든 뒤, 이전 배열의 모든 원소를 새 배열로 복사한다. 이때의 삽입 연산의 수행 시간은 어떻게 될까?
배열이 가득 차 있는 경우의 삽입 연산
배열이 가득 차 있는 경우를 생각해보면, 배열에 N개의 원소가 들어 있을 때 새로운 원소를 삽입하려면 O(N)이 걸린다. 크기가 2N인 배열을 새로 만들고, 기존의 모든 원소를 새 배열로 복사해야 하기 때문이다!
하지만, 보통 가득 차있는 경우는 드물고, 대다수의 경우 배열에 가용 공간이 존재하고 이때 삽입 연산은 O(1)이 걸린다!
두 가지 경우를 포함한 전체 수행 시간을 구하기 위해서,상환 시간이라는 개념을 이용하면 쉽게 구할 수 있다. 최악의 경우는 가끔 발생하지만, 한 번 발생하면 그 후로 꽤 오랫동안 나타나지 않으므로 비용(수행 시간)을 분할 상환한다는 개념이다.
위의 경우, 배열의 크기가 2의 제곱수가 되었을 때 원소를 삽입하면 용량이 두 배로 증가한다. 배열의 크기가 1, 2, 4, 8, 16 , ... , X일 때 새로운 원소를 삽입하면 배열의 용량이 두 배로 증가하고, 이 때 기존의 1, 2, 4, 8, 16 , ... , X개의 원소 또한 새로운 배열로 복사해주어야 한다. 이 원소들은 1부터 X가 될 때까지, 혹은 X부터 1이 될때까지 두 배씩 증가/감소하는 수열이다. 이때, X+X/2+X/4+X/8+...+1의 합은 대략 2X와 같다. (이 식이 정확하게 이해가 안감)
따라서, X개의 원소를 삽입했을 때 필요한 시간은 O(2X)이고, 이를 분할 상환해보면, 삽입 한 번에 필요한 시간은 O(1)이다. 상수 시간이 소요되다가, 배열의 원소가 2의 제곱수가 되었을 때만 O(2X) 비용이 소요된다.
logN 수행 시간
이진 탐색을 생각해보자. 이진 탐색은 N개의 정렬된 원소가 들어 있는 배열에서, 원소 x를 찾을 때 사용된다. 먼저 원소 x와 배열의 중간값들을 비교한다. x==중간값을 만족하면 이를 반환한다. 총 수행 시간은 N을 절반씩 나누는 과정에서 몇단계 만에 1이 되는지에 따라 추정된다.
N=16
N=8
N=4
N=2
N=1
2^k=N을 만족하는 k가 무엇인지를 구하기 위해, log를 사용한다. 이처럼, 어떤 문제에서 원소의 개수가 절반씩 줄어든다면, 그 문제의 수행 시간은 O(logN)이 되 가능성이 크다. 여기서, 로그의 밑이 2인데, big-O에서는 로그의 밑을 고려할 필요가 없으므로 무시하면 된다.
재귀적으로 수행 시간 구하기
int f(int n){
if(n<=1){
return 1;
}
return f(n-1)+f(n-1);
}
이 경우, 함수가 두 개이므로 성급하게 O(n^2)라고 생각할 수 있다. 하지만, 답은 틀렸다.
수행 시간을 추측하지 말고 코드를 하나씩 읽어 나가면서 수행 시간을 계산해보면, f(4)를 구할 때, f(3)은 f(2)를 거쳐서 결국 f(1)까지 도착한다.
트리의 깊이가 N이고, 각 노드(함수 호출)는 두 개의 자식 노드를 가지고 있다. 따라서, 깊이가 한 단계 깊어질 때마다 이전보다 두 배 더 많이 호출하게 된다.
root (level=0)일 때, 노드 1개, (2^0)
level=1일 때, 노드는 2개, (2^1)
level=2일 때, 노드는 4개, (2^2)
level=3이 때, 노드는 8개, (2^3)
이므로, 전체 노드의 개수는 이를 다 더한 2^0+2^1+...+2^n = 2^(n+1)-1의 식으로 표현된다. 수행시간은 O(2^n)이 될 것이다. 다수의 호출로 이루어진 재귀 함수에서 수행 시간은 보통 O(분기^높이)로 표현되곤 한다. 로그와는 달리, 지수에서는 밑을 무시할 수 없다. 2^2n과 2^n은 매우 다르다.
처음에 j는 n-1번 반복하다가, 점점 줄어들어 1이 된다. 따라서, (n-1)+(n-2)+...+1=(n-1)(n-2)/2가 되므로 O(n^2)이다.
(2) 코드가 무엇인지 파악하기
코드 자체가 무엇을 의미하는지를 생각한다. 이 함수는 j가 i보다 큰 모든 (i,j)쌍을 반복하여 출력한다. n=8이라 가정하면,
다음과 같이 출력된다. 이는 n*n의 절반 크기인 n^2/2크기의 행렬처럼 보인다. 따라서, O(n^2)시간이 걸린다.
(3) 평균을 이용한 방법
바깥의 루트는 n번 반복한다. 안쪽 루프는 얼마나 많은 일을 하고 있을까? 바깥 루프에 의존적이지만, 평균을 구해볼 수 있을 것이다. 1,2,3,4,...,n의 수열에서, 평균값은 대략 n/2가 된다. 따라서, 안쪽루프의 평균 반복횟수는 n/2이고, 이 루프는 총 n번 수행되므로 전체 수행횟수는 n^2/2, 즉 O(n^2)가 된다.
/* 예제 8 */
여러 개의 문자열로 구성된 배열이 주어졌을 때,
각각의 문자열을 먼저 정렬하고 그 다음에 전체 문자열을 사전순으로 다시 정렬하는 알고리즘.
<틀린 분석>
각 문자열을 정리하는데 O(NlogN)이 소요되기 때문에, 모든 문자열을 정렬하는 데 O(N*NlogN)이 소요될 것이다. 그 후, 사전순으로 정렬하면 O(N^2logN+NlogN)-> O(N^2logN)이 될 것이다.
왜 틀렸을까? N을 서로 다른 두 가지 경우에 혼용하여 사용했기 때문이다.
<정답>
가장 길이가 긴 문자열의 길이를 s라 하고, 배열의 길이를 a라 한다.
각 문자열을 정렬하는 데 O(slogs)가 소요된다.
a개의 문자열 모두를 정렬해야 하므로, 총 O(a*slogs)가 소요된다.
문자열 두 개를 비교하는 데 O(s)시간이 소요되고, 총 O(aloga)번을 비교해야 하므로, 사전순으로 정렬할 때, O(a*sloga)가 소요된다.
위의 두 부분을 더해주면, 전체 시간 복잡도는 O(a*s(loga+logs))가 된다.
/* 예제 9 균형 이진 탐색 트리 */
int sum(Node node) {
if (node==null) {
return 0;
}
return sum(node.left) + node.value + sum(node.right);
}
(1) 코드의 의미 파악하기
트리의 각 노드를 한 번씩 방문한 뒤에, 각 노드에서 상수 시간에 해당하는 일을 수행한다. 따라서, 수행 시간은 노드의 개수와 선형 관계에 있다. n개의 노드가 있다고 가정할때, 수행 시간은 O(n)이 된다.
(2) 재귀호출 패턴분석
함수에 나온 트리는 균형 이진 탐색 트리이다. 총 n개의 노드가 있다면 깊이는 대략 log n이 된다. 재귀 함수에 분기가 여러 개 존재할 경우, 수행 시간은 일반적으로 O(분기^깊이)가 되므로 이 수식에 따르면 수행시간은 O(2^logN)이 된다.
정수로 구성된 수열 S=(a1, a2, ... , an)가 주어졌을 때, S의 부분 수열이란 S에서 임의로 k개의 원소를 순서적으로 선택한 수열로서 인덱스가 1 ≤ i1 < i2 < ... < ik ≤ n 의 조건을 만족하는 수열(ai1, ai2, ... , aik) 을 말한다.
증가 부분 수열(increasing subsequence)이란, 이러한 부분 수열 중에 ai1 < ai2 < ... < aik 의 조건을 만족하는 수열이다.
최장 증가 부분 수열 (longest increasing subsequence - LIS) 문제는 이러한 증가 부분 수열 중 길이가 가장 긴 수열과 그 길이를 구하는 것이다.
예를 들어서, S={25,12,18,6,13,16,29,17} 에서 최장 증가 부분 수열 중 하나는 {12,13,16,17}이며 길이는 4이다. 물론, 길이가 4인 다른 부분 수열들이 존재할 수도 있다. {12,13,16,29} 도 길이 4를 가진 최장 증가 부분 수열이다.
이 문제에서는, 최장 증가 부분 수열이 여러 개가 있더라도 임의의 답을 하나만 구한다고 가정한다.
Q. 만약 우리가 주어진 수열의 모든 부분 집합으로 구성된 수열을 다 고려하고, 각 수열이 증가 부분 수열인지를 체크하여 증가 부분 수열들 중에서 가장 긴 부분 수열을 고른다면? (exhaustive search)
A. 원소의 개수가 n인 수열의 부분 집합 개수는 적어도 2^n개이므로, 일일이 다 구한다면 O(2^n)의 이상의 시간이 걸림.
동적 계획법
그렇다면 이 문제를 동적 계획법으로 해결하고자 한다. 그러기 위해서 우선 재귀적인 공식을 수립해야 한다.
hi 를 원소 ai로 끝나는 최장 증가 부분 수열의 길이라고 정의하자.
그렇다면, 우리가 원하는 최장 수열 증가 부분 수열의 길이 h는 a1로 끝나는 최장 증가 부분 수열의 길이 h1, a2로 끝나는 최장 증가부분 수열의 길이 h2, ... , an으로 끝나는 최장 증가 부분 수열의 길이 hn 중 가장 큰 값이 될 것이다.
가상적인 아주 작은 값 a0이 있다고 가정하면, 다음과 같이 되기 때문에
최장 증가 부분 수열의 길이는 아래와 같다.
간단한 예시를 보며 더 자세히 알아보도록 하겠다. S= {9,5,2,8,7,3,1,6,4}
i
0
1
2
3
4
5
6
7
8
9
수열 ai
- ∞
9
5
2
8
7
3
1
6
4
길이 hi
0
1
1
1
2
2
2
1
3
3
전 값 pi의 인덱스
2
2
3
6
6
우리가 구하는 최장 증가 부분 수열의 길이는 3이고, 그 수열은 (2,3,6), (2,3,4)가 될 것이다. (전 값의 인덱스를 따라감)
각 hi를 구하기 위해서는, ai와 그 앞에 있는 (i-1)개의 원소들 ai-1,...,a1과 비교해야 하므로전체 시간 복잡도는 O(n^2)
임을 알 수 있다.
int longest (int s[]) {
int i,j;
int h[MAX]={0,} ,p[MAX]; //h는 부분 수열의 길이, p는 전 값의 index
int max=0,index;
for(i=1;i<MAX;i++){
for(j=0;j<i;j++){
if(s[i]>s[j] && h[i]<h[j]+1){
h[i]=h[j]+1;
p[i]=j;
}
for(i=1;i<MAX;i++){ //최대 부분 수열의 길이 찾기
if(max<h[i]){
max=h[i];
index=i;
}
int lis[MAX]; // 최대 부분 수열을 저장하는 배열
i = max;
while(index!=0) {
lis[--i]=s[index];
index=p[index];
}
printf("longest increasing subseq");
for (i=0;i<max;i++) printf("%d ", list[i]);
printf("\n");
return max;
}