최소 스패닝 트리(Minumum Spanning Tree - MST)란,
1. 그래프의 모든 정점이 간선으로 연결되어 있고
2. 그래프 안에 사이클이 포함되지 않은
스패닝 트리 중 최소 cost의 합으로 만들어진 신장 tree를 말한다.
Kruskal Algorithm 은, 최소 스패닝 트리를 구하는 방법 중 하나로,
각 단계에서 그래프의 모든 edge 중에서 최소의 가중치를 갖는 edge를 선택하는 greedy algorithm 이다.
시작 정점을 정하고 가까운 정점을 선택하면서 트리를 구성하는 프림 알고리즘과 달리,
크루스칼 알고리즘은 시작점을 정하지 않고 최소 cost의 간선을 차례대로 대입하면서 트리를 구성하기 때문에
cycle check 를 꼭 해주어야 한다! (프림 알고리즘은 cycle이 생기지 않는다. )
알고리즘을 개괄적으로 이해하기 위해, 예제를 풀어보자.

0. 다음은 우리가 풀어야 할 그래프이다.
변 옆의 숫자는 가중치를 가리키고, 현재 edge에 아무것도 포함되지 않음.

1. 가장 가중치가 작은 변(AD or CE 중 아무거나)을 선택하여 edge에 포함시킨다.

2. 이제 CE 변이 가장 짧은 변이므로, edge에 포함시킨다.


3. 같은 방식을 반복하여 고르면 다음 변은 DF이므로 edge에 포함시키고,
그 다음으로 가장 짧은 변은 AB와 BE인데 임의로 AB를 고른다. (cycle만 없으면 상관없다!)
BD는 cycle을 구성하기 때문에 빨간색으로 표시하였다.

4. 다음으로 가장 짧은 변은 BE이다. edge에 포함시킨다. BC와 DE, EF가 cycle을
구성하므로 빨간색으로 표시하였다.

5. 끝내, 빨간색이 아닌 edge 중 더 작은 cost를 가진 edge EG를 연결하며 알고리즘이 종료된다.
edge의 개수가 정점 V -1 이 되었으므로 MST 가 완성되었다!
step 0) 모든 edge를 끊어서 가중치 작은 순서대로(오름차순) 정렬한다.
step 1) 정렬된 간선을 순서대로 선택한다.
step 2) 만약 edge가 서로소 부분집합인 두 개의 정점을 잇는다면,
두 개의 부분집합을 merge하고 해당 edge를 solution에 추가한다.
step 3) 모든 정점들의 부분집합이 merge될 때까지 step 1 ~ step 2 과정을 반복한다
이처럼 high-level 알고리즘을 보면 어렵지 않으나, 코드로 구현하기 위해서는
cycle을 확인할 때 Union-Find(Disjoint-Set) 자료구조를 이용해야 한다.
위의 알고리즘에서 서로소 집합에 있는 2개의 정점을 잇는다는 것은 cycle이 없다는 것을 의미한다.
이에 대한 자세한 설명을 이어서 해보도록 하자.
Union-Find Operations for disjoint sets. (서로소 집합 자료 구조)
서로소 부분 집합(disjoint - set)으로 나누어진 원소들에 대한 정보를 저장하고 조작하는 자료 구조이다.
이 자료구조에서 사용하는 연산은 다음과 같은 세가지로 나누어진다.
* U={0,1,2,...,n-1} 이라는 집합이 있다고 가정하고, U에 속하며 서로 전부 서로소인(disjoint) 부분집합 S0,S1,...,Sk-1 이 있다고 가정한다.
- init(n) : 원소 한개를 가진 n개의 집합들로 초기화한다.
- find(x) : 어떤 원소가 주어졌을 때, 이 원소가 속한 집합을 반환한다. 주로 "대표"하는 원소를 반환하므로, find값을 비교하면 이 원소들이 서로 같은 집합에 속하는지를 판단할 수 있다.
- union(x,y) : 두 개의 집합을 하나의 집합으로 합친다. x와 y집합에 대해 이 연산을 하면, find(x)=find(y)가 된다.
Example 1) U={0,1,2,...,9}이라고 할 때, 다음 연산을 하시오.
- init(10) : S0={0}, S1={1}, S2={2}, ... , S9={9}
- find(1) = 1, find(7) = 7
- union(1,7), union(2,5), union(0,3) : S0={0,3}, S1={1,7}, S2={2,5}, S3={4}, S4={6}, S5={8}, S6={9}
- find(7) = 1, find(3) = 0 (바로 위의 union을 한 후 find를 했을 경우)
Example 2) Connected Components (점진적으로 연결된 요소)
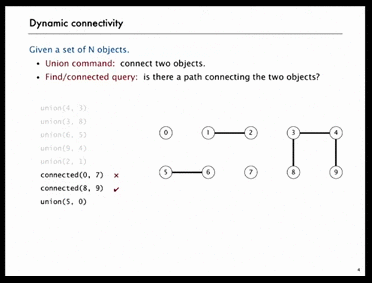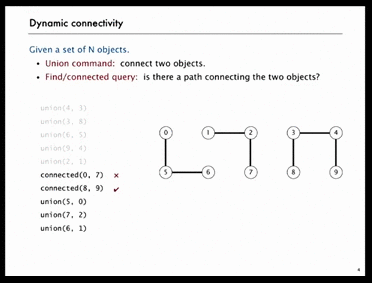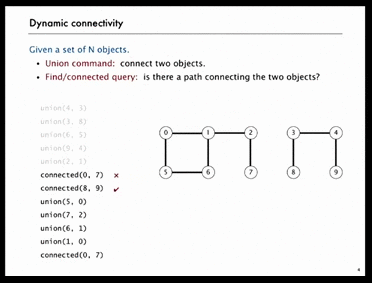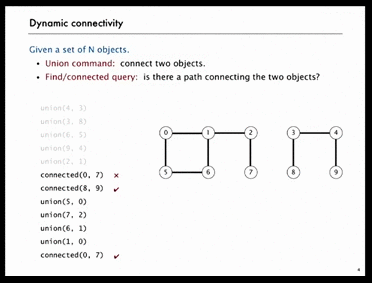

왼쪽의 GIF를 보자.
10개의 원소에 대해 5번의 union을 한 후, object[0]과 object[7]은 연결되지 않았고 object[8]과 object[9]는 연결이 되어있다.
그런데 4번의 union을 더 한 후, object[0]과 object[7]은 연결이 되어있다.
이처럼, 서로 disjoint했던 object의 각 집합은 union을 한 후 연결 상태로 바뀌게 된다.
다음과 같이, 점 p에서 q까지 grid point(교차점)를 통해 갈 수 있는 경로를 알아보고 싶다고 하자. 이 때, 위에서 배운 함수 세 가지를 응용하여 값을 구한다. 이러한 과정을 컴퓨터가 연산을 통해 계산한다.
- union(u,v) : 두 개의 grid point를 잇는다.
- find(u) : grid point u를 가진 set을 찾는다.
- path(u,v) : u와 v point를 잇는 경로가 있는가?
Kruskal Algorithm에 활용한 union - find
이제, 실제 알고리즘을 구현해보면서 이해해보도록 한다.
void kruskal (int n, int m, set_of_edges E, set_of_edges &F){
index i,j;
set_pointer p,q;
edge e;
Sort the m edges in E by weight in non-decreasing order; // 오름차순으로 간선 정렬
F={0};
init(n); /* Initialize n disjoint subsets. */
while (number of edges in F is less than n-1){ //간선의 개수=정점의 개수-1까지가 최대
e=edge with least weight not yet considered;
i,j=indices of vertices connected by e;
p=find(i);
q=find(j);
if (!equal(p,q)){
union(p,q);
add e to F;
}
}
}

← 왼쪽의 GIF를 보면 더 잘 이해할 수 있다.
오름차순으로 정렬된 edge를 순서대로 선택해나가고, 이 edge와 연결된 정점의 index를 각각 i와 j라고 한다. 각각의 정점을 init(n)함수를 통해 원소 1개짜리 서로소 집합인 부분집합으로 나누고, 이를 계속해서 union(p,q) 함수를 통해 병합해나간다. 정점이 전부 병합될 경우 while문은 종료된다.
우선, find(i)와 find(j) 값이 같다는 건, (i,j) edge를 추가할 경우 cycle이 생긴다는 뜻이다. 더 자세하게 말하자면, find 함수의 값은 해당 부분집합의 대표 값을 말한다. 따라서, 이 두 개의 값이 같다는 건 서로 같은 집합에 속한다는 것을 말한다. (두 부분집합을 병합한다면 cycle이 생기게 될 것이다!)
왼쪽의 GIF에서 보여지는 자료구조는 "up-tree" 구조인데, tree의 root가 대표값으로 간주된다. (find(x)연산과 일맥상통) / root 노드가 서로 다른 집합끼리 union할 경우, 하나를 다른 한 쪽의 자식으로 넣어서 두 트리를 합치게 된다.
| index | 0 | 1 | 2 | 3 | 4 |
| parent | -1 | 0 | 0 | 1 | 3 |
find함수는 대표 root가 나올 때까지 따라가는 함수인데, 위의 표와 같이 index를 계속 따라가서
parent가 -1 값을 가질 때까지 따라가게 된다. (root는 parent 값 -1)
root를 추적하는 과정에서, 해당 tree의 높이만큼 따라가게 될 것이라는 것을 알 수 있다.
int find(int i){ //parent[i] 만날 때까지 계속 거슬러 올라간다.
for (;parent[i]>=0;i=parent[i]);
return(i);
}
void union(int i,int j){ // 병합
parent[f(i)]=f(j);
}Time complexity
- Kruskal Algorithm
최악의 경우는 edge의 개수 m이 n(n-1)/2개일 경우이다.
W(n) = O(mlogm) = O(n^2logn)
- Find & Union

최악의 경우는 트리가 한 줄로 이루어졌을 때, (비대칭 트리, 연결리스트의 형태처럼 됐을 때) 즉, 모든 트리의 노드가 바로 뒤 노드를 가리키고 있을 때이다.
union(0,1)만 한 뒤 find(0) 연산 시 : for문 한 번만 돌면 된다.
union(0,1), union(1,2)를 한 뒤 find(0) 연산 시 : for문 두 번 돌면 된다.
union(0,1), union(1,2), union(2,3)를 한 뒤 find(0)연산 시 : for문 세 번 돌면 된다.
...
이런 식으로 n번 연산을 할 경우, find 연산 시 맨 끝의 root 노드를 찾기 위해 모든 부모 링크를 따라가야 하는 비효율성이 발생한다.
-> union() : W(n) = O(n^2)
-> find() : W(n) = O(n^2)
Weighted union tree (가중치 유니온 법칙)
위의 find & union 변질 트리 생성 문제를 더 효율적으로 해결하기 위해, 가중치를 고려한다.
Rule : wUnion(i,j)에서 트리 i 보다 트리 j가 노드 수가 더 적다면, i가 j의 부모가 되게 한다.
반대의 경우 j가 i의 부모가 되게 한다.
노드의 수가 많은 트리가 더 적은 트리의 parent(root)가 되게 한다. (노드 수에 가중치를 둠)

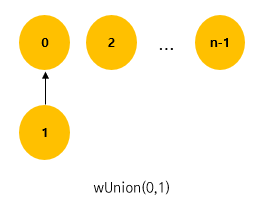

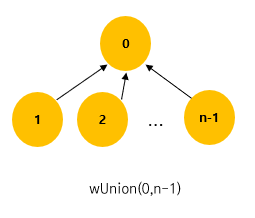
위 과정처럼, tree는 더 많은 쪽의 노드를 가진 tree에 속하게 된다.

h(T)는 tree T의 높이를 말한다. 다음과 같이, h(T)는 log_2 (n)만큼의 최대값을 가진다.
간단한 예시를 들어보자.
n=8인 tree T의 높이가 최대가 되게끔 가중치 union 법칙을 사용하여 구성해보도록 한다.
(node가 8개이고, h는 최대 log_2 (8)=3이 될 것이다. )
wUnion(0,1), wUnion(2,3), wUnion(4,5), wUnion(6,7)
wUnion(0,2), wUnion(4,6)
wUnion(0,4)



그림으로만 봐도 직관적으로 이해가 될 것이다. 처음에, 노드의 개수가 같으므로 첫번째 트리가 부모가 되게끔 하였다.
그 후, 계속해서 tree의 개수가 더 작은 쪽(같을 때는 왼쪽 노드들)에 트리를 포함시킨다.
이 때, find(7)=3을 했을 때 worst case이고, height와 같다.
(1) 이제 node의 개수 대신 tree의 height를 이용할 수 있다.
(2) find(x) 연산은 root를 찾기 위해 부모를 타고 올라간다.
만약 이 때, root node까지 순회하다가 방문한 각 node들이 직접 root를 가리키도록(포인터) 갱신하도록 한다면,
모든 노드들은 같은 대표 노드를 공유하게 될 것이다. = path compression (amortized)
'Personal Study > Computer Algorithm' 카테고리의 다른 글
| 동적계획법 (Dynamic Programming) - (2) 최장 증가 부분 수열 (LIS) (0) | 2019.04.22 |
|---|---|
| 동적 계획법 (Dynamic Programming) -(1) 이항계수 (0) | 2019.04.22 |
| 허프만 코드 (Huffman Code) (1) | 2019.04.21 |
| 배낭 문제 (Fractional Knapsack and 0-1 Knapsack Problem) (0) | 2019.04.21 |
| 다익스트라 알고리즘 (Dijkstra algorithm) (0) | 2019.04.07 |