* 해당 정리 및 요약본은 Andrew Glassner의 "Deep Learning : From Basics to Practice Volume 1,2"를
기반으로 제작된 것을 밝힙니다. *
Basic Probability Concepts


[Simple Probability]
다트를 던지면 무조건 벽에 꽂힌다고 가정하고, 확률은 모두 동일하다고 하자.
이 때, 다트가 붉은색 영역에 꽂히는 사건을 'A'라고 하면, A의 확률 P(A)는 붉은 영역과 전체 영역의 넓이의 비로 나타난다. 이렇게, 사건 하나가 일어날 확률 P(A)를 A의 simple probability / marginal probability라고 한다.
[Marginal Probability 주변 확률]

어떤 하나의 사건이 일어날 단순한 확률. 아무 조건이 붙지 않는 확률을 말한다.
[Conditional Probability 조건부 확률]

벽에 그림이 추가되어 초록색 영역이 생겼다고 가정하자. 이제 사건은 한 개가 아니라, 두 개이다. (시행은 한 번)
다트가 초록색 영역에 꽂히는 사건을 'B'라고 할 때, 조건부 확률 P(A|B)는 다트가 꽂힌 곳이 B의 영역 안일 때, 이 영역이 A 안에 있을 확률을 말한다.
-> 조건부 확률 P(A|B)는, 다시 말해 어떤 사건 'B'가 일어난 게 알려져 있을 때 다른 사건 'A'가 일어날 확률을 나타낸다.
-> A, B를 input으로 받고, probability를 return하는 algorithm이라고도 표현할 수 있다.
[Joint Probability]

P(A, B)의 경우는, 두 개의 서로 다른 사건 A와 B가 동시에 일어날 확률을 나타낸다.
위의 그림의 경우 전체 영역 중, A영역과 B영역이 intersect하는 부분에 다트가 꽂힐 확률을 말한다.
* Conditional Probability와 Joint Probability

Confusion matrix
[Simple Classifier]

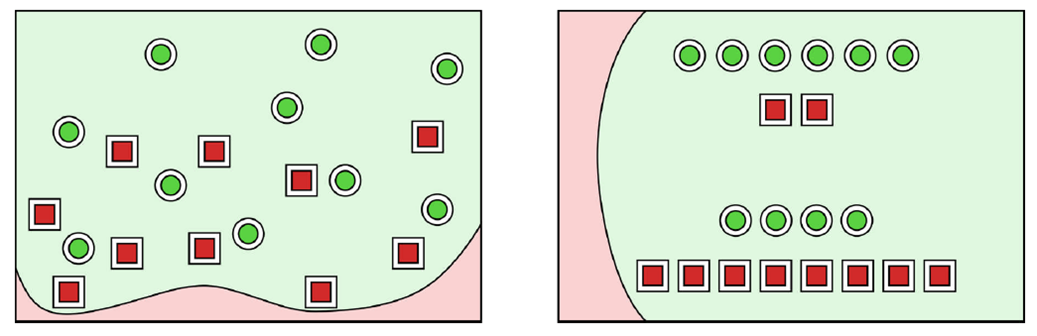
왼쪽 그림은 2D data sample을 나타낸다.
Classifier는, data sample을 input으로 받아 어떤 카테고리에 속하는지 output으로 출력한다.
Classifier를 build한다는 것은, 오른쪽 그림과 같이 data sample들을 동일한 것끼리 묶는 boundary curve를 찾는 것이다.
이 챕터에서는 output이 positive / negative인 경우만 고려한다.
현재 2D data sample은 모두 빨간색 / 초록색이므로 초록색인 경우를 Positive라고 가정한다.

위 그림처럼, dataset에서 20개의 sample을 사용한다고 가정하자. 실제 classifier는 이전 그림과 달리, curve의 양쪽(위아래)에 positive, negative가 섞여있게 된다. 왼쪽 그림의 화살표는 "positive" 방향을 가리키며, 각 sample들의 position을 무시한 채, count하기 편리하게 재배치한 그림이 오른쪽의 schematic version이다.
(실제 확률을 계산하는 데 관여하는 것은 sample의 수이기 때문에 두 diagram은 같다!)
이 sample들 중 어떤 sample은 맞는 결과가 나왔고, 어떤 sample은 틀린 결과가 나왔다. 이를 제대로 잘 분류하기 위해서, classifier를 수정하거나 새로 만드는 등의 작업을 거쳐야 한다. 따라서, 이러한 error들을 효율적으로 characterizing하는 것이 중요하다!
[Confusion Matrix 혼동행렬]
classifier의 정확성을 알아보기 위해, 점들을 4가지의 category로 분류한다.
- True Positive : 제대로 분류된 positive 경우
- False Positive : negative인데 positive로 분류된 경우
- False Negative : positive인데 negative로 분류된 경우
- True Negative : 제대로 분류된 negative 경우

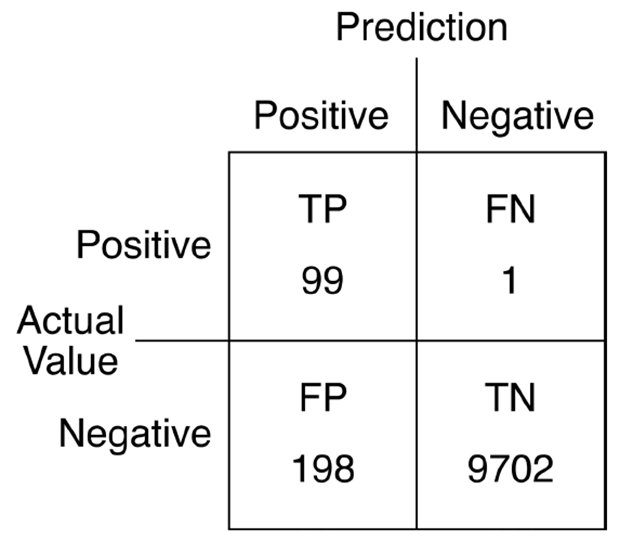
Confusion matrix는 위에 언급된 4개의 값들로 만들어진 2 by 2 matrix이다.
(Confusion matrix를 작성할 때, 형식에 대한 universal agreement가 없기 때문에, 늘 label을 주의깊게 확인해야 한다!)
[Interpreting the Confusion Matrix]
ex. medical diagnosis의 경우를 예시로 들어, positive는 어떤 사람이 병에 대해 증상이 있는 것이고, negative는 그 사람이 건강하다는 것을 나타낸다고 하자. 또한, 우리는 보건 관련 직원이고, morbus pollicus, 줄여서 MP라는 상상 속 병이 있다고 가정하자. MP에 걸린 모든 사람은 그들의 엄지손가락을 제거해야 하고, 그러지 않으면 몇시간 내에 죽는다!
따라서, 우리가 사람들이 MP에 걸렸는지 아닌지를 진단하는 것이 여기서 매우 중요한 문제가 될 것이다.
(병에 걸렸는데 손가락을 자르지 않으면 그 사람이 죽고, 병에 걸리지 않았는데 굳이 손가락을 자르게 될 수 있는 것임)

이 병의 진단을 confusion matrix로 표현하면 위의 그림과 같다. 각 matrix의 cell에 numbers를 부여하고, 이 값들을 사용하여 population과 test에 질문을 할 수 있다. 이 때 "어떤 질문"을 하느냐가 굉장히 중요하다.
예를 들면, "MP를 가진 사람 중에 몇 명이나 정확하게 분류되었는가?"라는 질문은 겉보기엔 유용해보이지만, 잘못된 결과를 나타낼 수도 있다. 만약 우리의 test가 항상 True를 return했다고 가정하면, 위의 질문에 대한 대답은 "100%"가 될 것이다. 다시 말해, test는 위 질문에 대한 수행을 완벽하게 해냈지만, MP를 가지지 않았는데도 positive한 결과가 나온 (False Positive) 모든 사람들의 수많은 경우들을 전부 무시한 게 되는 것이다.
이 질문 외에, "우리가 제대로 진단한 건강한 사람은 몇명이었는가?"라는 질문을 생각해보자. 마찬가지로, 우리는 지금 한 경우의 진단만을 확인하고 있다. 만약 우리가 모든 사람에게 False 진단을 내린다면, 단순히 우리의 test는 "100%" 정확하다는 결과를 내보낼 것이다. 모든 건강한 사람은 "건강하다는 진단"을 받겠지만, MP를 가진 사람들은 전부 죽게 될 것이다.
"제대로 된 질문"을 하는 것은 굉장히 어렵고, 이러한 실수를 하기 쉽다. 이러한 wrong question problem을 해결하기 위해, 여러 해결 방법이 있다.
Measuring Correctness
어떤 measure를 사용하느냐에 따라 classifier의 정확도가 99%가 되기도 하고, random guess보다 못한 수준이 되기도 한다. 다음은 classifier의 quality를 characterize하는 개념들이다.
[Accuracy]

Accuracy는 전체 sample data 중 제대로 정답을 맞춘 경우(True positive / True negative)의 비율을 나타낸다.
즉, 이 classifier가 얼마나 정확한지를 알려준다. 하지만, false negative와 false positive 중 어디서 prediction이 잘못되었는지를 나타내지 못한다는 단점이 있다.
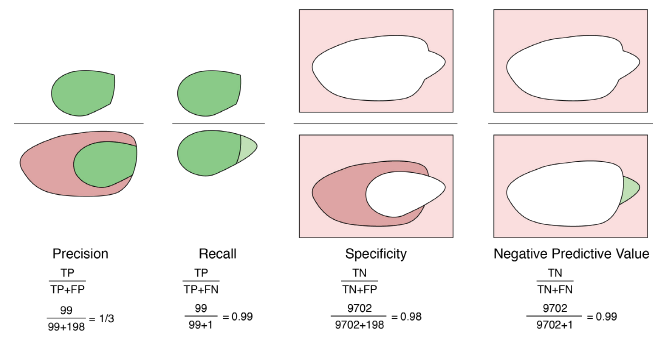
[Precision (positive predictive value) / PPV]

Precison은 positive로 예측한 sample값들 중 실제로 positive인 sample들의 비율을 말한다.
만약 precision이 1보다 작다면, positive가 아닌 값들을 positive로 labeling했다는 것이 된다. (unnecessary operations)

Precision의 단점은, 모든 ground truth positive값들 중에 classifier가 얼마나 이들을 찾아냈는지 알 수 없다는 것이다.
(Ground truth : 사람이 수작업을 통해서 만들어낸 original data. 직접 수집하고 정제한 후 labeling한 data를 말함)
[Recall (Sensitivity, hit rate, true positive rate)]

Recall은 실제로 positive인 sample들 중에서, positive로 제대로 예측된 sample들의 비율을 말한다.
recall이 1.0이라는 것은, 모든 positive event를 다 찾아냈다는 것을 의미한다. recall 값이 떨어질수록 positive event를 더 많이 놓쳤다는 것이 된다. 위의 MP예제에 적용해본다면, recall이 1.0이하면 MP에 걸린 어떤 사람을 제대로 진단해내지 못했다는 것이 된다.

Recall은 실제로 negative한 값들이 어떻게 예측됐는지 무시해버린다는 단점이 있다.
[Precision and Recall]

500page의 wiki에 "dog training"이라는 phrase를 검색한다고 가정하자.
만약 우리의 search engine의 page가 dog training에 대해 return한다면 positive, return하지 않는다면 negative라 한다.
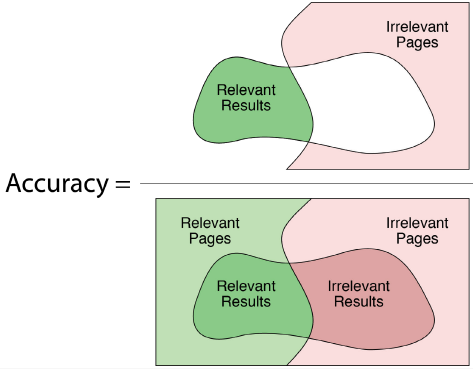
accuracy의 경우, 전체 비율 중 제대로 labeled된 비율이기 때문에 위와 같다.

precision의 경우,
[Perfect Precision]

Precision과 recall은, machine learning에서 많이 쓰이는 measure 중 하나이다.
하지만, 만약 precision만 쓸 경우에는 perfect precision이라는 문제가 발생할 수 있다.
만약 Classifier가 수많은 sample들 중 가장 positive일 확률이 높은 하나의 sample만 positive로 분류하고, 나머지 sample들을 모조리 negative로 분류한다고 가정하면, precision은 100%가 될 것이다.
-> 이는 precision이 positive로 분류된 sample만을 고려하기 때문에 발생하는 문제이다.

[Perfect Recall]

[F1 score]

precision과 recall을 합쳐, 둘의 조화평균으로 나타낸 것을 F1 score라고 부른다. 위의 그래프를 보면, F1 score는 한 쪽의 점수가 아무리 높더라도 다른 한 쪽의 점수가 0에 가까워지면 급격하게 감소함을 확인할 수가 있다.
Applying the Confusion Matrix
실제 예시를 들어 위의 개념들을 적용해보자. 위의 MP 병에 대해 우리가 가진 classifier인 진단 test를 시행해보았다고 하고, 이 마을에서 약 1%의 사람만 MP를 가지고 있음이 이미 확인되었다고 가정한다.
(1) MP를 가진 사람들의 경우
99%의 확률로 MP는 제대로 진단되어 TP rate는 0.99이고, 따라서 MP를 가졌지만 제대로 진단되지 않은 사람의 비율 FN rate는 1%(0.01)라고 하자.
(2) MP에 걸리지 않은 사람들의 경우
실제로 걸리지 않아서 건강하다고 진단받은 사람의 경우인 TN rate는 0.98, 실제로 걸리지 않았는데 걸렸다고 진단받은 사람의 경우인 FP rate는 0.02라고 하자.

어떤 사람이 양성(positive) 판정을 받았을 때, 이 사람이 정말로 MP에 걸렸는지 아닌지를 알고 싶다면, confusion matrix를 build하여 알아볼 수 있을 것이다. 하지만, 위 그림처럼 matrix를 만드는 것은 잘못된 결과를 도출해낼 것이다.
-> 위의 matrix에서는 MP에 걸릴 확률과 걸리지 않을 확률을 동일하게 가정하고 있다. 이 마을에서는 실제로 오직 1%의 사람들만 MP가 발병하였다. 실제 positive와 negative의 비율을 고려해야 한다!

진짜 confusion matrix를 구현하기 위해서는, 전체 인구 10,000명을 100명의 감염자(1%)와 9900명의 비감염자로 나누고, 다시 진단 test의 결과에 따라서 이를 나눠야 한다. 이렇게 해서 나뉜 값들이 진짜 confusion matrix의 원소가 된다.
이제 제대로 된 chart가 생성되었으니, 아까의 질문에 대답을 얻어낼 수 있다.
Q. test에서 양성의 결과가 나왔을 때, 그 사람이 MP에 실제로 걸려있을 조건부 확률은 무엇인가?
A. TP / TP + FP이므로, 98 / 99+198 = 약 33%의 결과가 나온다.
-> 이 결과를 보면, 약 300명 중 200명은 잘못된 결과를 도출한다는 뜻이므로, 우리의 test가 거의 잘못 진단을 내린다는 것을 알 수 있다 ! 이는 10,000명의 사람들 중 건강한 사람의 비율이 높았기 때문에 발생한 결과이다.
-> 이보다 더 비싸고 정확한 test를 해야 한다는 것으로 이해하면 됨.

오른쪽 그림을 보면, MP를 가진 사람들을 대부분 positive라고 제대로 진단해내지만, MP에 걸리지 않은 198명의 사람들을 positive라고 잘못 진단해낸 걸 볼 수 있다.
'Lab Study > Machine Learning' 카테고리의 다른 글
| [Deep Learning] 4. Bayes' Rule (1) | 2020.07.07 |
|---|---|
| [Deep Learning] 2. Randomness and Basic Statistics (0) | 2020.07.01 |